Recently, an industry association came to us to help them build a portal for receiving member data and a data warehouse for sharing the insights gained from that data. Snowflake was the obvious platform to support the data warehouse, but the client was also interested in using Snowflake to process and store files submitted by the member organizations.
The design called for files of specified formats to be uploaded to a portal which would then send them on to common tables in Snowflake for processing and quality assurance.
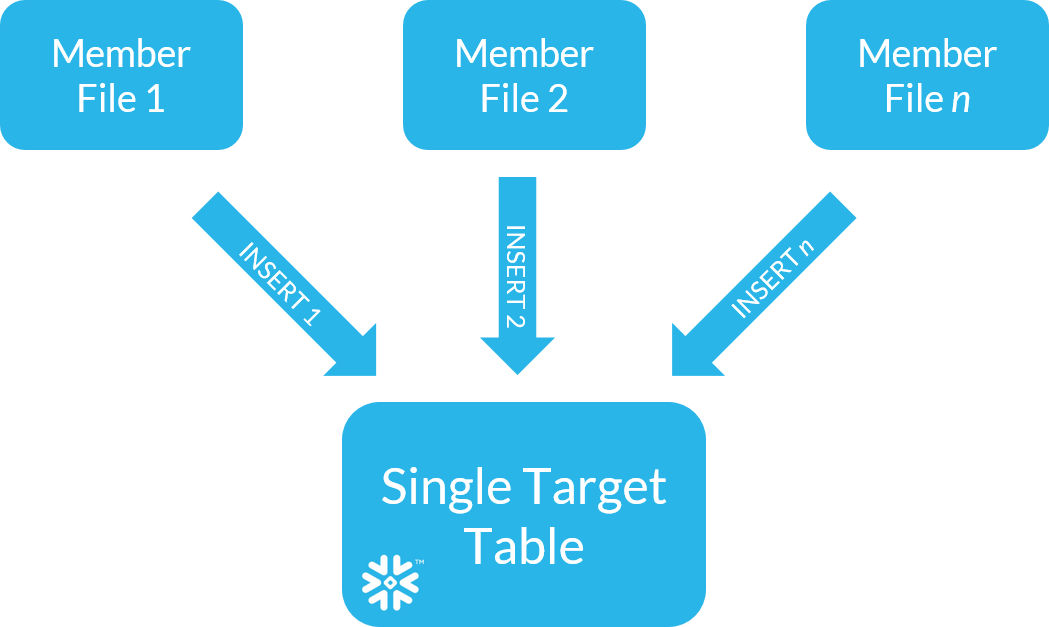
In DEV, the architecture worked fine, but we hit an unexpected snag when we scaled up. The association will have hundreds of members submitting multiple large files on a monthly cycle, so there would be n processing threads trying to simultaneously insert records into the same table in Snowflake. Once our testing got to around n > 50, the process started failing sporadically and we encountered the following error message:
000625 (57014): Statement ‘018c3a53-00a8-9df1-0000-0cc5001ac9ee’ has locked table ‘DATA_QUALITY_REPORT’ in transaction 1558031235691 and this lock has not yet been released. Your statement ‘018c3a53-007f-37d7-0000-0cc5001abcf2’ was aborted because the number of waiters for this lock exceeds the 20 statements limit. If the error message is not clear, enable the logging using -o log_level=DEBUG and see the log to find out the cause. Contact the support for further help.
The bit that really caught our attention was, “the number of waiters for this lock exceeds the 20 statements limit.” Snowflake has established a reputation for performance and concurrency, so many users aren’t aware that Snowflake limits the number of certain types of DML statements that target the same table concurrently.
To be clear, this error only occurs with simultaneous writes of any type to the same table; the source involved could be a file in a stage, another table, or a view. Snowflake has a built-in limit of 20 queued DML statements, including:
In researching and interacting with Snowflake support on this issue, we learned that the root cause of this error is not in the writing of micro-partitions to cloud storage as might be implied by the error message, but rather a constraint in the Global Service Layer’s metadata repository database. Remember, when a micro-partition is written, statistics and profile information about that micro-partition are also written into the metadata repository. This enables the fast query performance and pruning that made us all fall in love with Snowflake in the first place. In order to maintain ACID compliance, these records must be written in a transactionally safe manner.
The simplest fix for this issue would be to perform the insert from each file sequentially instead of concurrently, however, we had an SLA in this case where members require confirmation that their files have been processed with no errors within one minute of their submission, regardless of how many other members were submitting files at the same time. If the files were to be processed sequentially, the SLA would be missed whenever there was a heavy load.
If you encounter this challenge, you will need to architect around it. So how do you overcome concurrent write limits in Snowflake? In our case, we took advantage of the member file submission portal to give each file a unique integer identifier that would be appended as a suffix onto the file name.
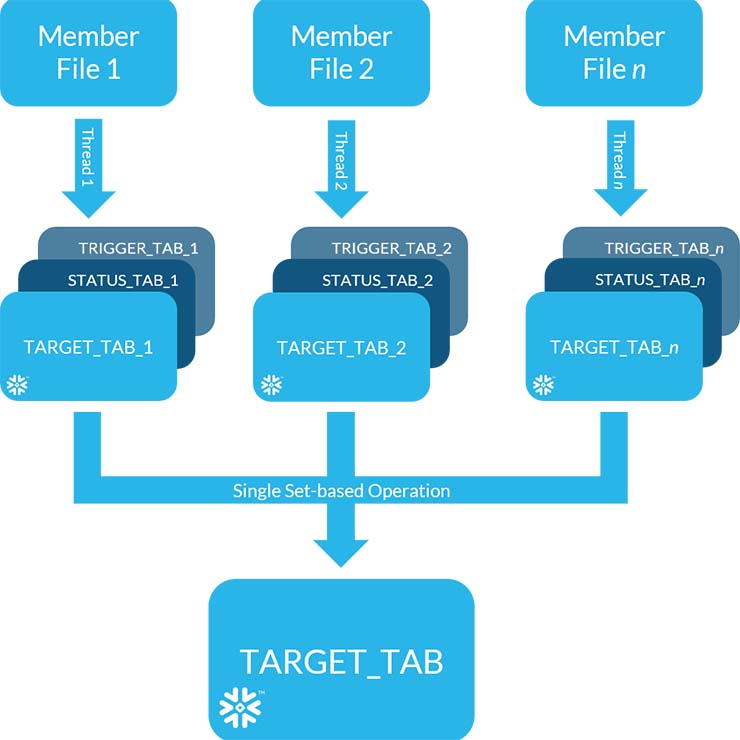
The idea is to create a unique table in Snowflake to receive each submitted file. The data in each of these tables is then individually processed and checked for errors. This processing creates two accessory tables for each file, one to hold the quality assurance status or other details from the processing, and a second one that is created upon the successful completion of the process for that file. At this point, the proper status can be communicated back to the portal to meet the notification SLA.
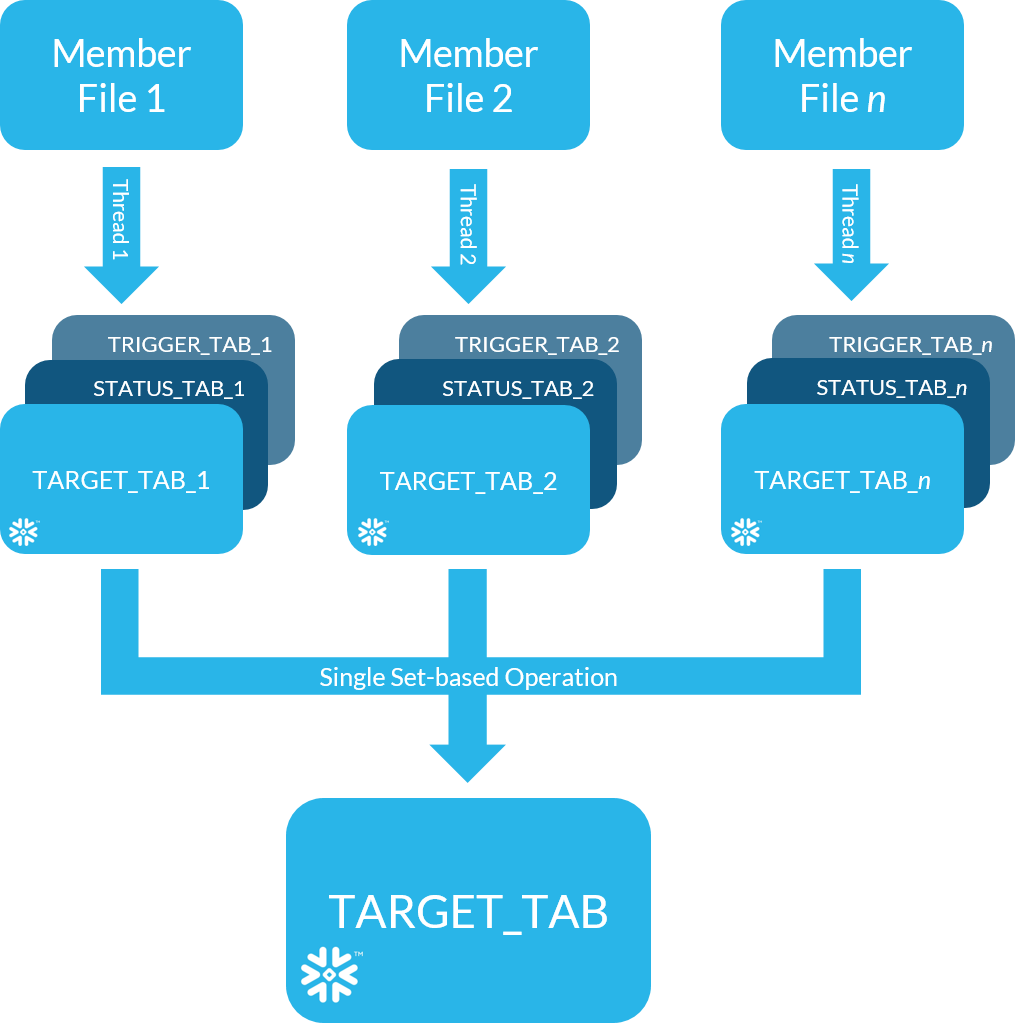
Afterwards, at a regular point in time (once a minute, once an hour, once a day, etc.), we check the INFORMATION_SCHEMA for the existence of any tables with the naming convention of TRIGGER_TAB_###. For every such table found, we know to take all the related TARGET_TAB_### tables, and in a single set-based operation, union them together and insert them into the final target table. Because this happens as a single DML statement, no queue is created and the error is avoided.
At this point, we execute several QA scripts to ensure that the data added to the final TARGET_TAB now contains all the records from the several TARGET_TAB_### tables without duplications or omissions. Once these tests are passed, we drop all the TARGET_TAB_### tables and any accessory tables that were created with them. This ensures that the next periodic set-based insert to the final target table doesn’t catch the same file twice.
Always keep in mind that the Snowflake Data Warehouse is designed for high-volume analytical processing workloads including high-concurrency reading. Snowflake is not a high-concurrency Online Transactional Processing (OLTP) database.



